Troubleshooting Azure Load Balancer Data Path Availability Degradation
A real-world production incident involving Azure Load Balancer data path availability degradation affecting MQ traffic routing and backend service connectivity in a multi-cloud enterprise platform.
Sowmya Narayan
5/10/20262 min read
Introduction
In distributed enterprise environments, load balancers play a critical role in routing traffic reliably between applications, middleware systems, and backend services.
Even temporary degradation in load balancer health can create:
connectivity interruptions
request failures
MQ communication instability
cascading application issues
We recently encountered a production alert involving severe Azure Load Balancer data path availability degradation affecting MQ traffic routing in a cloud-based enterprise platform.
In this blog, I’ll walk through:
how the issue was detected
what the alert indicated
potential impact on services
troubleshooting observations
lessons learned from handling infrastructure-level connectivity degradation
The Alert
The operations team received critical infrastructure alerts indicating:
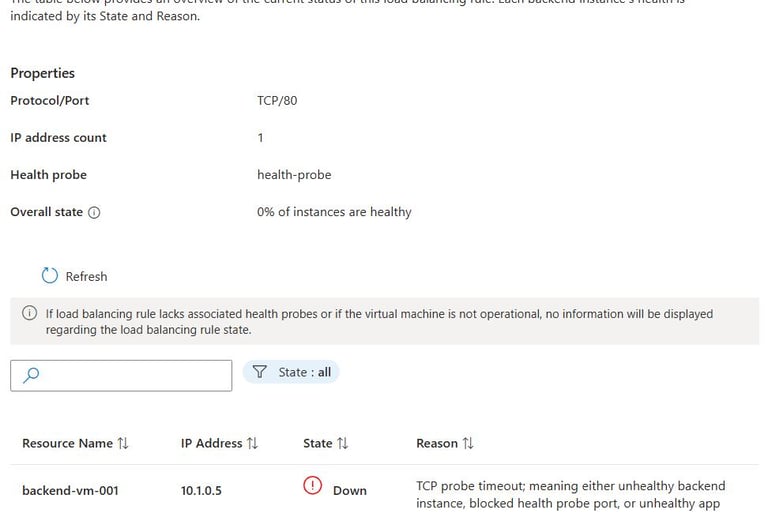
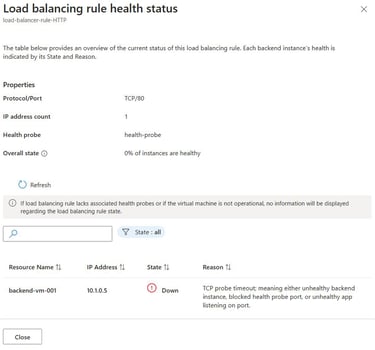
Average Load Balancer data path availability is degraded
The alert specifically referenced:
Azure Load Balancer frontend listeners
MQ traffic ports
backend connectivity degradation
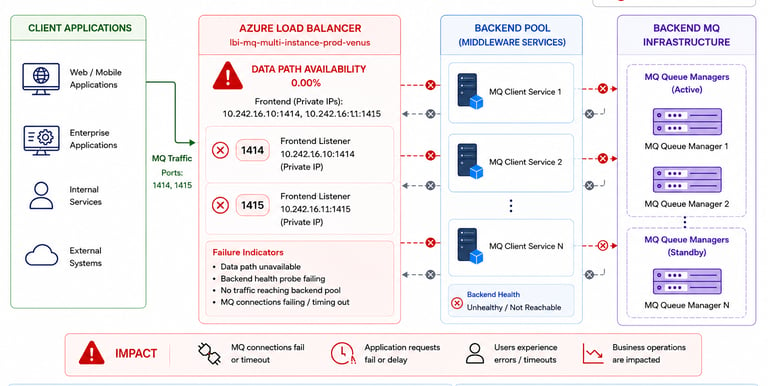
Example alert:
Average Load Balancer data path availability for loadbalancer is 0.00%
Frontend:
10.x.x.x:1414
10.x.x.x:1415
What the Alert Means
Azure Load Balancer data path availability measures whether traffic can successfully flow through:
frontend IPs
backend pools
health probes
routing infrastructure
A value of:
0.00%
indicates that traffic routing through the load balancer was completely unavailable during the alert window.
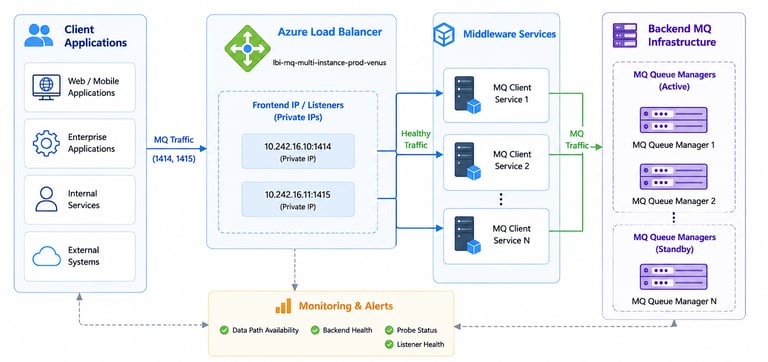
Architecture Overview
The environment relied on Azure Load Balancers to route MQ traffic between:
client applications
middleware services
backend MQ infrastructure
When load balancer availability degraded:
MQ channels became unstable
requests timed out
backend communication failures increased
Detection and Monitoring
The issue was identified through infrastructure monitoring alerts.
The alerts indicated:
backend connectivity instability
degraded data path availability
unhealthy frontend listeners
potential packet routing failures
Potential Service Impact
Since MQ traffic depended on the affected load balancer listeners:
application communication could become intermittent
MQ connectivity could fail
backend transaction processing could be delayed
downstream APIs could experience timeout errors
In enterprise environments, even short-lived MQ interruptions can impact:
authentication services
transaction processing
notifications
real-time integrations
Investigation Observations
During troubleshooting, teams reviewed:
Azure Load Balancer metrics
frontend listener health
backend pool availability
MQ channel status
network connectivity monitoring
The affected frontend listeners included ports commonly used for MQ communication:
1414
1415
These ports are frequently associated with enterprise MQ traffic routing.
Infrastructure Failure Illustration
The degradation likely interrupted:
packet forwarding
backend routing
persistent MQ connections
client communication flows
Why Load Balancer Health Matters
Load balancers are often treated as stable infrastructure components, but they are critical dependency layers in distributed systems.
When load balancer routing becomes unhealthy:
applications may still appear running
pods may remain healthy
databases may stay available
Yet customer-facing functionality can still fail because traffic cannot properly reach backend systems.
Operational Learnings
This incident highlighted several important operational lessons.
1. Infrastructure-Level Failures Can Cascade Quickly
Even temporary load balancer degradation can impact:
MQ communication
APIs
authentication workflows
downstream integrations
2. Observability Must Include Network Layers
Application monitoring alone is not enough.
Infrastructure visibility into:
load balancers
health probes
backend pools
network paths
is equally important.
3. MQ Systems Are Highly Sensitive to Network Instability
Persistent MQ connections can become unstable during:
routing interruptions
packet loss
backend connectivity degradation
4. Alert Correlation is Critical
Correlating:
MQ timeouts
API failures
infrastructure alerts
load balancer metrics
helps accelerate incident troubleshooting.
Preventive Improvements
Following the incident, teams reviewed:
load balancer monitoring thresholds
backend health probe configurations
MQ connection resilience
retry handling strategies
network observability improvements
Additional monitoring enhancements were also considered for frontend listener availability tracking.
Final Thoughts
In cloud-native enterprise environments, load balancers are critical infrastructure components that directly impact application reliability.
In this incident:
Azure Load Balancer data path availability degraded to 0%
MQ traffic routing became unstable
backend communication reliability was impacted
Strong infrastructure observability, rapid alerting, and proactive network monitoring remain essential for maintaining stable distributed systems.