Production Incident: PostgreSQL Outage Impacting Login and Microservices Platform
A real-world production incident involving PostgreSQL outages that impacted authentication systems, customer-facing applications, and backend microservices in a Kubernetes-based cloud platform.
Sowmya Narayan
5/9/20262 min read
Introduction
Modern cloud-native platforms heavily depend on managed database services for authentication, notifications, payments, and customer-facing operations.
Even a short database outage can quickly cascade into widespread service disruption across multiple microservices.
We recently faced a production incident where multiple PostgreSQL databases became temporarily unavailable, impacting:
login services
mobile and web applications
backend microservices
support operations
In this blog, I’ll walk through:
how the issue was detected
the impact on services
investigation and troubleshooting steps
the actual root cause
operational lessons learned from the incident
The Incident
At approximately:
4:17 AM
multiple production services started reporting persistence and database connectivity failures.
The operations team immediately received alerts indicating that several PostgreSQL production databases were unavailable.
Initial Alert Detection
The issue was detected through:
Grafana alerts
application log monitoring
service failure alerts
microservice health checks
The alerts indicated:
persistence layer failures
database connectivity issues
microservice instability
increasing API failures
Services Impacted
Several critical services were affected during the outage, including:
authentication services
email services
loyalty systems
notification services
payment-related services
customer account management systems
Since the authentication database was impacted, customer login functionality was also affected.
Customer Impact
During the outage window:
customers intermittently failed to log in
mobile and web platforms experienced disruptions
transactions and statements became temporarily unavailable
card management and payment operations were affected
Support representatives also faced issues while:
looking up customer information
accessing support portals
performing account operations
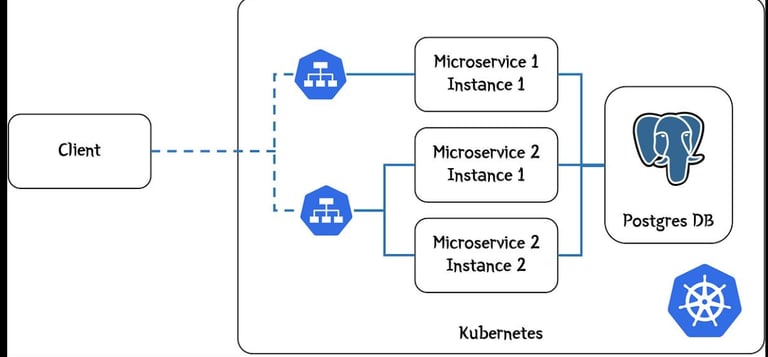
Architecture Overview
The platform architecture relied on multiple microservices communicating with dedicated PostgreSQL databases.
When database connectivity became unavailable:
application pods started failing
connection pools timed out
downstream APIs became unstable
Investigation and Troubleshooting
During investigation, the operations team observed:
Hikari connection pool timeout errors
persistence layer failures
microservice restart loops
intermittent database availability
Several impacted application pods were restarted to stabilize services.
Application Failure Analysis
Application logs showed increasing database connection failures and timeout errors.
Database Outage Observations
During the incident, multiple PostgreSQL instances became temporarily unavailable.
The affected databases included:
authentication databases
notification databases
email service databases
loyalty service databases
payment-related databases
Several database instances automatically recovered after short downtime intervals.
Root Cause Analysis
After investigation with the cloud provider support team, the actual root cause was identified.
The issue was caused by:
maintenance activity on managed PostgreSQL infrastructure
temporary database connectivity interruption during the maintenance window
cascading downstream application failures
The maintenance activity temporarily affected database availability, which caused multiple dependent services to become unstable.
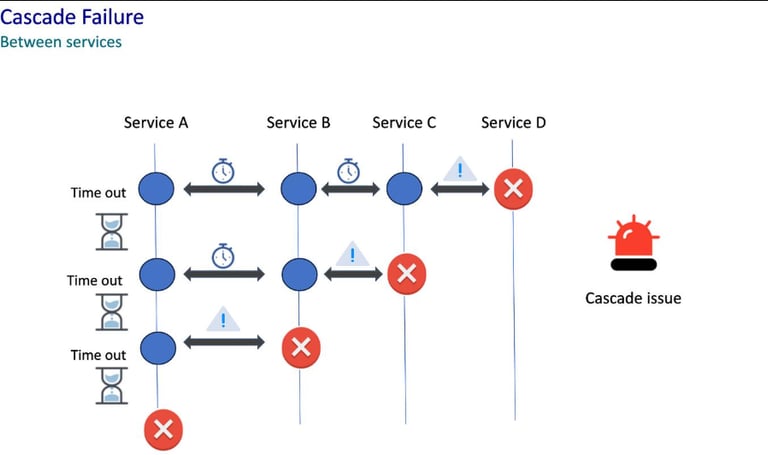
Cascading Failure Illustration
Since authentication and core business services depended heavily on PostgreSQL connectivity:
login systems failed
downstream APIs timed out
microservices became unstable
customer-facing applications experienced intermittent outages
Resolution
The issue auto-resolved once the maintenance activity completed.
To stabilize services and avoid recurring failures:
affected application pods were restarted
service health was revalidated
monitoring checks were reviewed
support cases were raised with the cloud provider for RCA confirmation
Key Learnings
This incident highlighted several important operational lessons.
1. Managed Cloud Services Can Still Introduce Downtime
Even fully managed database platforms can experience temporary maintenance-related disruptions.
2. Database Dependencies Create Cascading Failures
A short-lived database outage can quickly impact:
authentication
APIs
notifications
transactions
customer-facing applications
3. Strong Observability is Critical
Monitoring tools like:
Grafana
centralized logs
application alerts
helped quickly identify the impacted services and narrow down the issue.
4. Connection Pool Monitoring Matters
Hikari timeout monitoring provided early indicators of database connectivity degradation.
5. Incident Coordination is Essential
Rapid coordination between:
application teams
platform teams
database teams
cloud vendors
helped accelerate troubleshooting and recovery.
Preventive Improvements
Following the incident, the team reviewed:
database resilience strategies
monitoring thresholds
retry handling configurations
failover planning
cloud maintenance visibility
Additional observability improvements were also discussed for better proactive detection.
Final Thoughts
Cloud-native applications are deeply dependent on managed infrastructure services, and even short infrastructure disruptions can create widespread application impact.
In this incident:
managed PostgreSQL maintenance activity
temporarily interrupted database connectivity
resulting in cascading failures across multiple microservices and customer-facing systems
Strong observability, rapid incident response, and coordinated troubleshooting were critical in minimizing downtime and restoring services quickly.