Troubleshooting Message Queue (MQ) Timeout Issues Across Azure and GCP Datacenters
A real-world production incident involving Message Queue (MQ) timeout issues across Azure and GCP datacenters that partially impacted customer login services, backend APIs, and distributed microservices communication.
Sowmya Narayan
5/9/20263 min read


Introduction
Distributed systems running across multiple cloud datacenters can occasionally face transient network failures that are difficult to predict and troubleshoot.
We recently encountered a production incident involving intermittent MQ timeout issues across both Azure and GCP datacenters, which partially impacted customer login services and backend operations on our digital platform.
This issue affected:
customer login functionality
mobile applications
profile updates
transaction lookup services
CSR operations
In this blog, I’ll walk through:
how the issue was detected
monitoring and observability used during investigation
the actual root cause
impact analysis
lessons learned from the incident
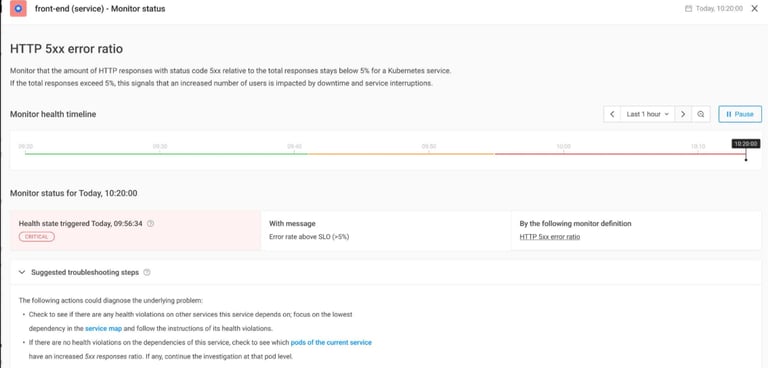
Alert Detection
The issue was initially identified through monitoring alerts triggered by elevated 5XX failure rates across microservices.
We observed:
increased HTTP 5XX errors
API timeout failures
elevated MQ timeout errors
customer login failures
Alert notifications were triggered automatically via monitoring systems.
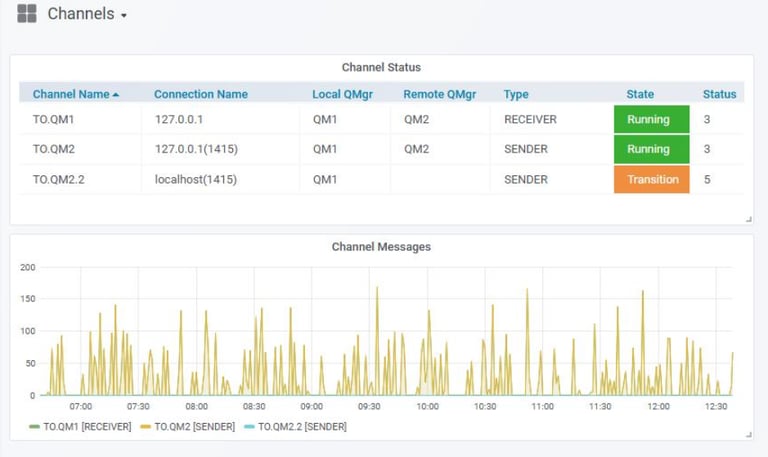
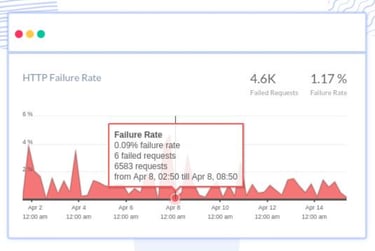
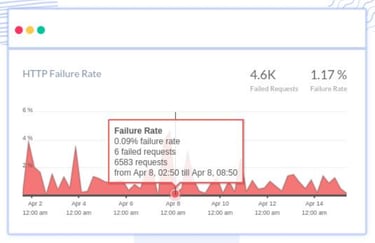
Monitoring Dashboard Observations
Our Grafana MQ dashboards immediately showed abnormal channel behavior across both Azure and GCP datacenters.
The dashboards revealed:
MQ timeout spikes
channel instability
intermittent connectivity disruptions
sudden drops in message flow
Customer Impact
Between approximately:
2:53 AM – 3:06 AM EST
customers experienced intermittent failures across multiple services.
Observed Impact
Customer login to secure site and mobile application was partially impacted
Approximately 557 unique customers faced login failures
Users already logged in experienced intermittent issues while:
updating profiles
viewing statements
checking transactions
accessing notifications
CSR agents also observed:
OOPS errors
customer lookup failures
intermittent backend processing issues
Application Error Investigation
During investigation, we analyzed logs in Elastic Stack and observed a large increase in authentication and timeout-related failures.
The logs confirmed:
timeout-related API failures
MQ communication delays
intermittent authentication processing failures
Failure Rate Analysis
Detailed request tracing showed a sudden spike in API failure rates during the impacted time window.
The failure rate temporarily crossed:
50% error rate
high request timeout thresholds
This directly correlated with the MQ connectivity disruption.
Root Cause Investigation
Further investigation with the Network Team identified the actual root cause.
The network tunnel between datacenters experienced a brief flap and temporary outage.
Network logs showed:
Oct 27 02:54:04:
EIGRP Neighbor Tunnel500 is down: holding time expired
Oct 27 02:56:11:
EIGRP Neighbor Tunnel500 is up: new adjacency
This temporary tunnel instability caused:
MQ communication interruptions
timeout failures
transient connectivity issues between Azure/GCP MQ and TSYS MQ
Why the Issue Impacted Multiple Services
The impacted microservices relied heavily on MQ communication for:
authentication workflows
transaction processing
profile management
backend service integration
When MQ connectivity became unstable:
requests started timing out
APIs returned 5XX errors
downstream services failed intermittently
Since the issue affected both Azure and GCP datacenters simultaneously, the impact spread across multiple dependent services.
Auto Recovery
One important observation was that the issue self-recovered after network connectivity stabilized.
Once the tunnel adjacency was restored:
MQ channels resumed normal operation
API error rates dropped
login services recovered automatically
No manual restart or failover activity was required.
Operational Learnings
This incident highlighted several important operational lessons.
1. Network Instability Can Cascade Quickly
A short-lived tunnel flap created widespread application-level failures across multiple services.
2. Strong Observability is Critical
Dashboards, logs, alerts, and tracing significantly reduced troubleshooting time.
3. Cross-Cloud Dependencies Need Careful Monitoring
Applications running across:
Azure
GCP
external MQ systems
must include robust network observability and redundancy planning.
4. MQ Health Monitoring is Essential
Real-time monitoring of:
MQ channels
queue depth
timeout rates
connectivity status
helps identify issues before customer impact becomes severe.
Preventive Actions
Following the incident:
Network Team performed RCA analysis
additional monitoring validations were added
MQ timeout alerting thresholds were reviewed
tunnel stability monitoring was improved
Final Thoughts
Transient network failures in distributed cloud environments can create large-scale application disruptions even when infrastructure itself remains healthy.
In this incident:
a temporary network tunnel flap
caused MQ timeout failures
which impacted customer login and backend services across Azure and GCP datacenters
Strong observability, rapid alerting, and coordinated troubleshooting between platform, application, and network teams were critical in quickly identifying and resolving the issue.