A real-world production incident involving JDBC connectivity failures and Hikari connection pool timeouts impacting authentication, notifications, and payment-related microservices across multi-cloud Kubernetes environments.
A real-world production incident involving JDBC connectivity failures and Hikari connection pool timeouts impacting authentication, notifications, and payment-related microservices across multi-cloud Kubernetes environments.
Sowmya Narayan
5/9/20263 min read
Introduction
In large-scale cloud-native environments, even temporary database connectivity disruptions can quickly impact multiple customer-facing services.
We recently encountered a production incident where several microservices across both GCP and Azure environments experienced JDBC connectivity failures, leading to:
Hikari connection pool timeouts
authentication failures
notification delivery issues
intermittent login disruptions
In this blog, I’ll walk through:
how the issue was detected
impacted services
troubleshooting observations
investigation findings
lessons learned from handling database connectivity issues in distributed systems
The Incident
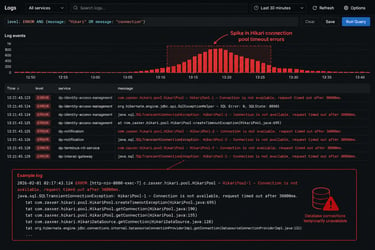
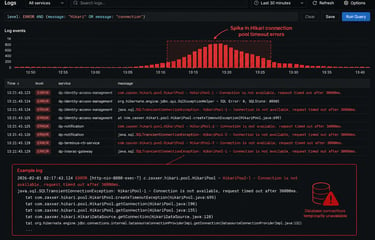
Multiple microservices across both GCP and Azure environments began experiencing JDBC connectivity failures, resulting in Hikari connection pool timeouts and intermittent service degradation.
Application logs started showing:
JDBC connection errors
Hikari connection pool timeout exceptions
intermittent database connectivity failures
Alert Detection
The issue was identified through:
Grafana Hikari pool alerts
JDBC error logs
application monitoring dashboards
Slack incident notifications
PagerDuty alerts
The monitoring dashboards revealed:
connection pool exhaustion
database timeout spikes
intermittent service instability
Impacted Services
Several important microservices were affected during the incident.
Authentication Services
Authentication systems experienced intermittent failures, impacting customer login functionality.
Notification Services
Notification systems responsible for:
emails
SMS
alerts
experienced intermittent delivery failures.
Customer Relationship Services
Services managing customer-to-account relationships and card mapping became unstable due to database connectivity interruptions.
Payment and Transfer Services
Payment-related services responsible for transaction routing and real-time updates also experienced temporary degradation.
Customer Impact
During the outage:
some customers were unable to log in to mobile and web applications
intermittent authentication failures were observed
notification delivery delays occurred
The outage caused approximately:
~30% login failures for a short duration
~1% overall user impact during the incident window
Architecture Overview
The platform architecture relied on multiple microservices communicating with PostgreSQL databases through JDBC connection pools.
When database connectivity became unstable:
Hikari pools exhausted available connections
requests started timing out
downstream services became unstable
Investigation Findings
During troubleshooting, the operations team observed:
JDBC timeout exceptions
Hikari connection pool exhaustion
intermittent PostgreSQL connectivity failures
service instability across both cloud environments
The affected microservices gradually stabilized after restarting the impacted application pods.
Hikari Connection Pool Timeouts
Application logs showed multiple Hikari connection pool timeout errors.
This indicated that:
database connections were either unavailable or delayed
connection pools could not obtain healthy connections
application threads started waiting for database access
Resolution
The operations team restarted all impacted microservices.
After the restart:
JDBC errors stopped
Hikari pools recovered
service stability returned
customer login functionality normalized
No additional customer impact was observed afterward.
Root Cause Investigation
The investigation identified that several microservices temporarily lost database connectivity during the incident.
A support case was raised with the cloud provider to investigate potential managed PostgreSQL infrastructure issues.
However, because the support case was opened after the telemetry retention period had expired, the cloud provider was unable to perform a detailed root cause analysis.
The final RCA remained inconclusive.
Why This Incident Was Challenging
This incident was difficult because:
the issue auto-recovered
logs were no longer available from the cloud provider
no permanent infrastructure failure was visible afterward
the issue affected multiple services across multiple cloud environments simultaneously
This is a common challenge in distributed cloud systems where transient infrastructure or networking issues disappear before full diagnostics can be captured.
Key Learnings
This incident highlighted several important operational lessons.
1. JDBC Connectivity Issues Can Cascade Quickly
Temporary database connectivity interruptions can rapidly impact:
authentication
notifications
payments
customer-facing APIs
2. Hikari Pool Monitoring is Extremely Valuable
Connection pool monitoring provided early visibility into database degradation before complete service failure occurred.
3. Fast Incident Escalation Matters
Cloud telemetry retention windows are limited.
Delays in opening support cases can make root cause analysis difficult or impossible.
4. Multi-Cloud Dependencies Increase Complexity
When applications span multiple cloud providers:
troubleshooting becomes harder
observability becomes critical
correlation across environments is essential
5. Restarting Services May Temporarily Restore Stability
Restarting affected pods helped refresh:
stale JDBC connections
exhausted pools
unhealthy application states
However, restarts should not replace proper RCA investigations.
Preventive Improvements
Following the incident, the team reviewed:
JDBC retry handling
Hikari timeout configurations
connection pool tuning
monitoring improvements
faster vendor escalation processes
Additional observability improvements were also planned for database connectivity monitoring.
Final Thoughts
Database connectivity failures in distributed cloud-native environments can create widespread application instability even when infrastructure appears healthy.
In this incident:
temporary JDBC connectivity disruptions
caused Hikari pool exhaustion
impacting authentication, notifications, and customer-facing services across multiple cloud environments
Strong observability, rapid incident response, and proactive database monitoring remain essential for operating reliable large-scale microservices platforms.